-1.png)

项目概述
llm.c 是一个GitHub项目,由Andrej Karpathy发起,旨在使用C语言和CUDA重新实现OpenAI在2019年发布的GPT-2(124M)模型。这个项目大约有4000行C/CUDA代码,通过高效的实现,能够在单个8X A100 80GB SXM节点上在大约90分钟内复现该模型,成本大约为20美元。
主要功能
模型复现:复现GPT-2(124M)模型,这是OpenAI发布的GPT-2系列中最小的模型。
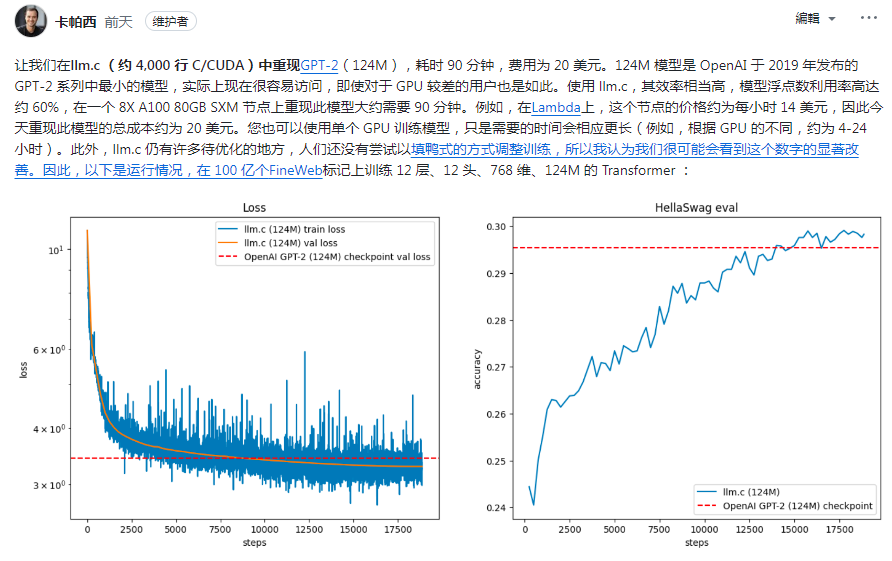
高效性能:llm.c 在模型浮点运算(flops)的利用率上达到了约60%。
低成本训练:使用Lambda实验室的硬件,每小时约14美元,复现模型的总成本约为20美元。
单GPU训练:支持使用单个GPU进行训练,只是所需时间会相应更长。
使用方法
环境配置:需要Linux操作系统,CUDA 12环境,以及Miniconda等。
数据集处理:使用特定的脚本处理FineWeb数据集,生成模型训练所需的token文件。
模型训练:通过编译后的llm.c程序,使用命令行参数配置训练过程,如批量大小、序列长度、学习率等。
结果评估:通过FineWeb验证数据集和HellaSwag准确性来评估模型性能。
适用场景
学术研究:研究人员可以利用llm.c来研究和理解大型语言模型的工作原理。
模型开发:开发者可以使用此工具来开发和优化自己的语言模型。
性能测试:在不同的硬件配置上测试模型的性能和训练效率。
适用人群
机器学习研究人员:对深度学习和自然语言处理有兴趣的研究人员。
软件工程师:具有C/CUDA编程经验,希望从事高性能计算的工程师。
学生:学习深度学习和模型训练的学生。
优缺点介绍
优点
成本效益:相比于其他平台,使用llm.c训练模型的成本较低。
高效实现:代码优化良好,能够实现较高的模型运算利用率。
易于复现:提供了详细的教程和指南,方便用户复现结果。
缺点
硬件限制:需要特定的GPU支持,可能不适合没有相应硬件的用户。
使用门槛:需要一定的技术背景,对新手可能不太友好。
功能限制:目前主要支持预训练,不支持聊天式微调等更高级的功能。
分类标签推荐:深度学习、自然语言处理、模型训练、CUDA编程、高性能计算
PuLID是一个新兴的ID保持项目,致力于提升ID保持效果并最小化对原始模型的影响。其核心优势包括高度一致性、多功能性、高保真度、稳定性和准确性,应用广泛。