-1.png)

SignLLM:全球首个多语种手语视频生成模型
模型概述:
模型名称:SignLLM
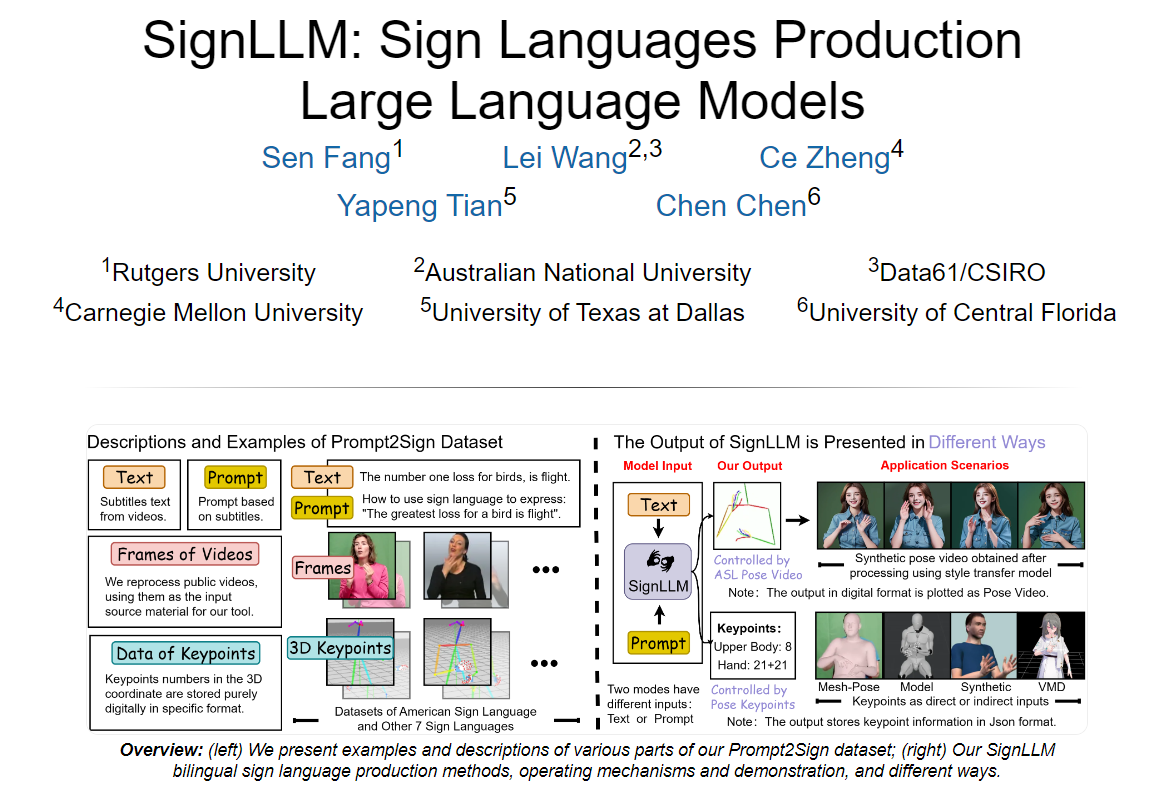
模型简介:SignLLM 是全球首个多语种手语视频生成模型,能够将文本或语音指令实时转化为手语视频,为听障人士提供沟通新方式。
主要功能:
功能一:实时文本或语音到手语视频的转换。
功能二:支持多种不同手语体系的视频数据生成。
功能三:利用大型语言模型的语义理解和生成能力,实现手语翻译。
使用方法:
步骤一:输入文本或语音指令。
步骤二:SignLLM 模型解析指令并转化为相应的手语视频。
步骤三:输出手语视频供听障人士观看和理解。
适用场景:
场景一:教育领域,为听障学生提供教学内容的手语版本。
场景二:公共服务,如医院、银行等,提供手语服务指南。
场景三:社交互动,帮助听障人士在社交媒体上进行交流。
适用人群:
人群一:听障或有听力障碍的人士。
人群二:手语翻译工作者和教育者。
人群三:对人工智能和辅助技术感兴趣的开发者和研究人员。
优缺点介绍:
优点一:突破性技术,为听障人士提供便捷的沟通方式。
优点二:支持多语种,有助于跨文化交流。
优点三:利用大型语言模型,具有强大的语义理解和生成能力。
缺点一:作为新技术,可能需要时间普及和优化。
缺点二:对于复杂或特定情境的手语翻译可能存在局限性。
SignLLM 的开发和应用,为听障人士提供了一种全新的沟通方式,有望在促进信息无障碍和社会包容方面发挥重要作用。随着技术的不断进步,SignLLM 有潜力成为听障社群的重要辅助工具。
Hallo是由复旦大学开发的一项前沿技术,专注于肖像图像动画。它利用先进的扩散模型生成逼真且动态的肖像动画,与传统的参数模型相比,Hallo技术提供了更为自然和流畅的面部动作。